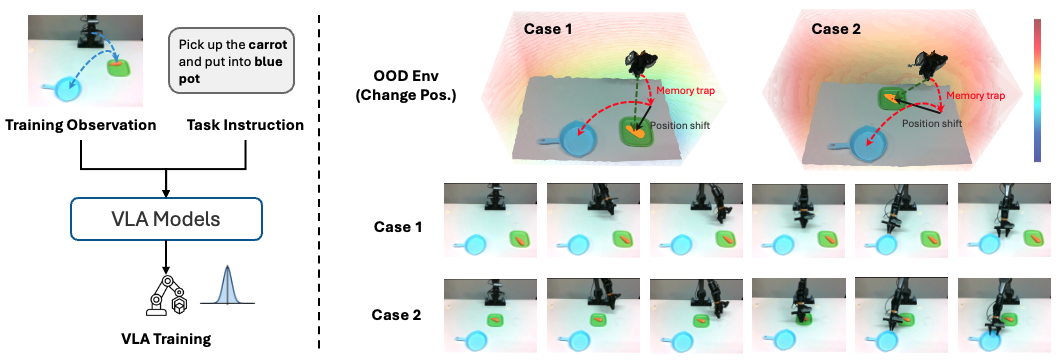
Vision-Language-Action (VLA) models have shown great performance in robotic manipulation by mapping visual observations and language instructions directly to actions. However, they remain brittle under distribution shifts: when test scenarios change, VLAs often reproduce memorized trajectories instead of adapting to the updated scene, which is a failure mode we refer to as the "Memory Trap".
This limitation stems from the end-to-end design, which lacks explicit 3D spatial reasoning and prevents reliable identification of actionable regions in unfamiliar environments. To compensate for this missing spatial understanding, 3D Spatial Affordance Fields (SAFs) can provide a geometric representation that highlights where interactions are physically feasible, offering explicit cues about regions the robot should approach or avoid.
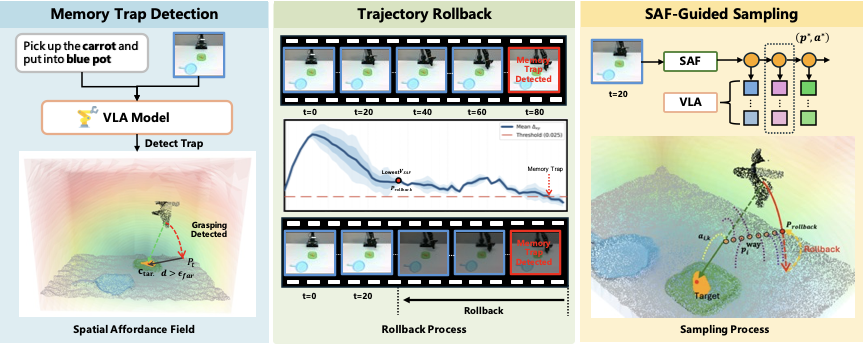
We therefore introduce Affordance Field Intervention (AFI), a lightweight hybrid framework that uses SAFs as an on-demand plug-in to guide VLA behavior. Our system detects memory traps through proprioception, repositions the robot to recent high-affordance regions, and proposes affordance-driven waypoints that anchor VLA-generated actions. A SAF-based scorer then selects trajectories with the highest cumulative affordance.
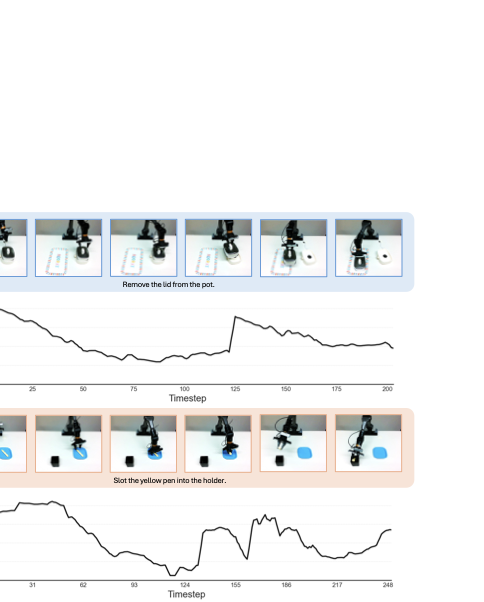
Extensive experiments demonstrate that our method achieves an average improvement of 23.5% across different VLA backbones (π0 and π0.5) under out-of-distribution scenarios on real-world robotic platforms, and 20.2% on the LIBERO-Pro benchmark, validating its effectiveness in enhancing VLA robustness to distribution shifts.